QA in AI Assisted Development: Safety through Deterministic Verification

To solve the Verification Crisis, teams must move from manual mocking to Runtime Context Sharing. By integrating BitDive via Model Context Protocol (MCP), AI agents gain access to real execution traces, allowing them to propose surgical fixes and self-verify their work against Real Runtime Data. This is more than just automation; it is the Deterministic Verification Layer required for the AI-native developer.
"We're now cooperating with AIs and usually they are doing the creation and we as humans are doing the verification. It is in our interest to make this loop go as fast as possible. So, we're getting a lot of work done."
. Andrej Karpathy: Software Is Changing (Again)
This quote describes a shift that is already visible in many teams. Code creation has accelerated. Verification and validation increasingly become the bottleneck.
With AI tools, writing code is often not the limiting factor anymore. The hard part is proving that what was generated is correct, safe, and maintainable.
Code Volume Growth and Test Review Challenges
To understand QA challenges, we should look at how code is produced. Testing is not isolated. It reflects development speed and development habits. If development accelerates, QA pressure grows too.
The Main Shift: Writing Has Become Cheap, Verification Has Become Expensive��
A common side effect of AI coding is rapid codebase growth without matching growth in quality. This is often described as "code bloat".
Some Facts:
- Explosive Growth in Code Volume (Greptile, 2025): The "State of AI Coding 2025" report recorded a 76% increase in output per developer. At the same time, the average size of a Pull Request (PR) increased by 33%. Physically, significantly more material arrives for verification and review than a person can qualitatively process.
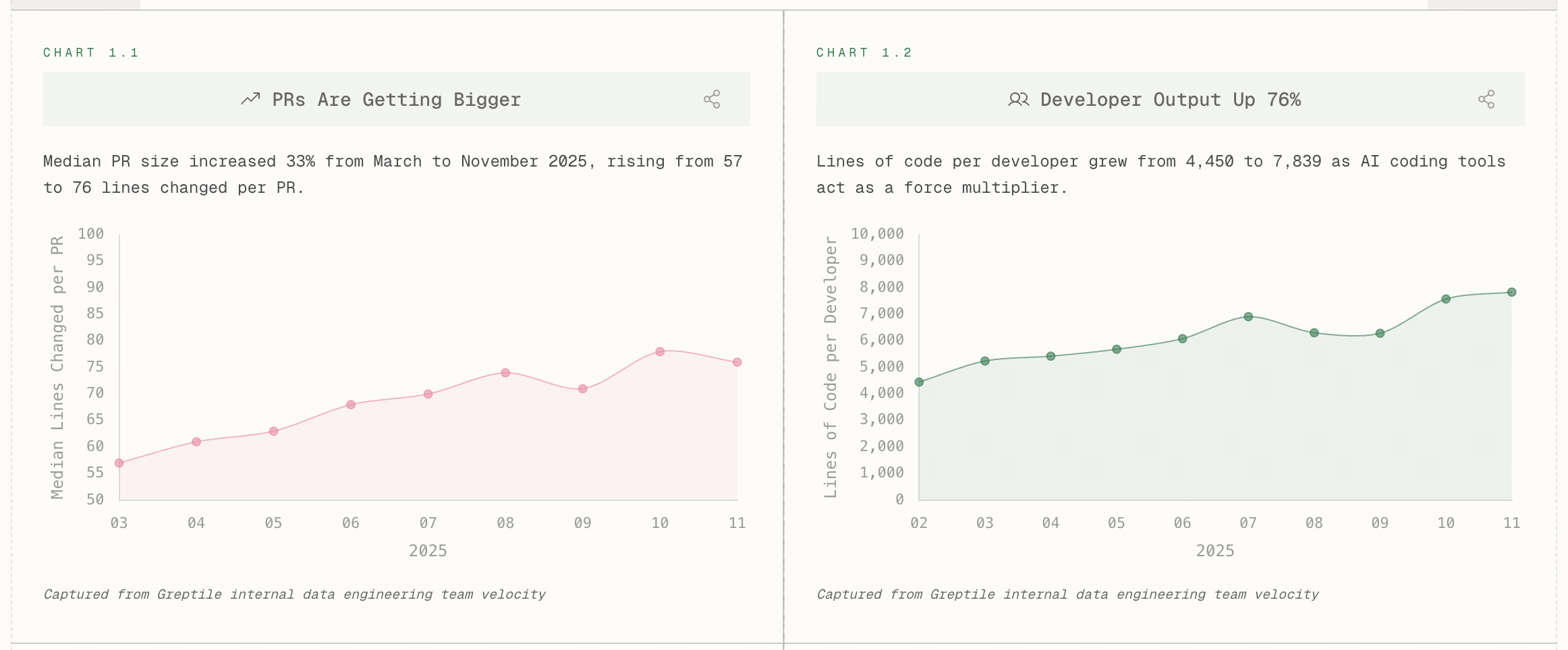 Figure: PR sizes are getting bigger and developer output has increased 76% (Greptile Internal Data, 2025)
Figure: PR sizes are getting bigger and developer output has increased 76% (Greptile Internal Data, 2025)
Other 2025 studies point in the same direction. A field experiment by Cui et al. (4,867 developers) reports a 26% increase in completed tasks and a 13.55% increase in code update frequency among AI assistant users. An analysis by Daniotti et al. on 30 million GitHub commits reports an overall increase in commit rate, with the largest effect (+6.2%) among experienced developers.
At the same time:
-
Code quality signals degrade (GitClear, 2025): A study covering 211 million lines of changed code (2020 to 2024) reports that the share of refactoring and code movement fell from about 25% to under 10% by 2024, while copy and paste style changes increased. This suggests teams spend less effort improving existing code structure and more effort adding new code on top.
-
Delivery stability can suffer (DORA, v2025.2): In "Impact of Generative AI in Software Development", DORA reports an estimated association: for every 25% increase in AI adoption, delivery throughput decreases by about 1.5% and delivery stability decreases by about 7.2%.
Anti-Patterns and "Review Fatigue"
Code generated by AI often contains structural security errors and architectural "crutches" that a human expert would never write. Errors become more subtle and difficult to detect, as AI writes syntactically correct but logically vulnerable code.
As the volume of generated code grows, human capacity for critical analysis decreases. The phenomenon of "Review Fatigue" sets in.
Engineers, seeing correctly formatted test code with clear function names and proper indentation, tend to trust it by default. The "Looks good to me" (LGTM) effect kicks in, where the reviewer's attention is dulled by the visual correctness of the generated solution, missing fundamental logical flaws.
When Tests Become Unmaintainable: The Knowledge Gap Problem
When test code grows faster than shared understanding, teams accumulate a critical knowledge gap.
Before AI tools, writing an automated test (unit, integration, or E2E) was a cognitive process. The engineer had to study requirements, understand component architecture, and formulate verification conditions. The test served as documentation of this understanding.
With AI assistants like GitHub Copilot or Cursor, hundreds of lines of test code can be generated in seconds (with a Tab press), skipping this cognitive stage.
The engineer receives a working test without passing its logic through their consciousness. When a test written by a human fails, the author (or their colleague) restores the logic, as it was conscious. When an AI-generated test fails, the engineer faces code they are seeing for the first time.
The team's collective knowledge about what exactly these tests verify approaches zero. This critically complicates Root Cause Analysis.
The "Safe Path" Trap and Mocking Hell
AI models, being probabilistic, strive to minimize the risk of syntax errors. The safest path for the model is to write a test that calls a function but checks minimal conditions.
A test can be syntactically correct and give a "green" result but not check the business logic for which it was created.
This gets worse with heavy mocking. AI often produces verbose tests with many mocks. Such tests can lock onto implementation details instead of behavior. Then refactors break tests even when user visible behavior stays the same.
Alongside classic hallucinations, AI introduces specific risks:
- Correctness illusion: A test looks valid and passes, but it does not verify the key business condition.
- Context drift: During maintenance, AI can "fix" a failing test so it passes again, but the new version may validate less than before, masking defects.
- Package hallucination and slopsquatting: Research reports that AI sometimes references non existent packages, and attackers can exploit that by publishing malicious packages under those names. See: arXiv 2501.19012.
- Responsibility blur: When a bug escapes, it becomes less clear who is accountable: the engineer, the reviewer, or the tool.
Test Maintenance Costs with AI-Generated Code
Maintenance Burden
Creating code is cheap, maintaining it is not. AI tests, especially those based on mocks, are tightly coupled to the internal structure of the code. When internals change (without changing external behavior), these tests fail. Considering that Code Churn (code rewriting) has doubled, "red" builds can be considered the norm.
In World Quality Report 2025-26, 50% of QA leaders using AI in test case automation cite "Maintenance burden & flaky scripts" as a key challenge in test automation (ranking question, base: 314). The report also notes that "Resources are continually being depleted by maintenance."
The same report shows that teams report only about one quarter of new automated test scripts as AI generated on average (base: 314). This combination can create a trap: faster creation without structural resilience, while maintenance pressure stays high.
How AI Changes Testing Practices: TDD and the Testing Pyramid
Traditional methodologies such as Test-Driven Development (TDD) are experiencing an existential crisis.
The essence of TDD has always been not just about verification, but about design. Writing a test before code forced the engineer to think through the interface and architecture. When AI creates implementation in seconds, this "thinking stage" is skipped.
Developers increasingly write (or create) tests after the code is already written, fitting them to the result of AI's work. This turns testing from a design tool into a tool for fixing the current state, whatever it may be.
Transformation of the Testing Pyramid
The classic "Testing Pyramid," which has been the industry standard for decades (many cheap Unit tests, few expensive E2E), is rapidly losing relevance.
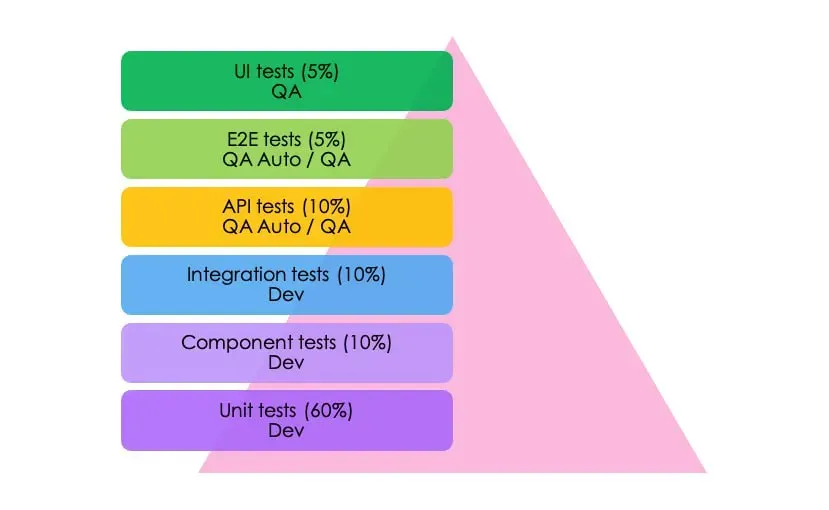
Fig. 1. Traditional paradigm (Testing Pyramid). This model, which assumes that 60% of tests should be unit tests, stops working effectively as the maintenance cost of the pyramid's base grows.
AI inverts the classic testing pyramid. Since AI writes code faster than humans, the bottleneck becomes not writing, but checking intentions. The role of unit tests (checking individual functions) decreases, as AI often writes syntactically correct but logically erroneous code. The emphasis shifts to integration and end-to-end (E2E) tests, where autonomous agents check the operability of the entire system as a whole, simulating user behavior.
The role of "specification" as a central artifact will increase. Not necessarily Gherkin (Cucumber), but the idea itself: first we fix the intention, then we create code and tests. Here Thoughtworks separately highlights spec-driven development as an emerging approach in AI-assisted workflow.
In an economy where coding approaches zero cost, value shifts from writing lines to Behavior Verification. An engineer's true significance is now determined not by the amount of code written, but by the ability to guarantee that the generated system does exactly what the business needs.
This shift requires rethinking quality metrics. Management traditionally focuses on Code Coverage. With AI, achieving an 80-90% coverage indicator has become trivial, but the correlation between high coverage and actual product quality has practically disappeared. This requires updating test-to-code ratio standards for AI-assisted development.
Integration and Contract Testing in Microservices
Contract Testing as the "Glue" of Microservices
Contract testing is becoming a critically important standard for microservices and API-First architecture. Its growing popularity, especially in the context of shift-left strategy, reflects the evolution and deepening specialization in quality assurance.
The Essence of the Difference: Integration testing checks real interaction of running services. Contract testing validates compliance with agreements (contracts) in isolation.
The Second Wind of Consumer-Driven Contracts (CDC)
Contract creation from traffic existed before, but often led to the creation of fragile tests that break from changes to any dynamic field (timestamp, session ID).
Consumer-Driven Contracts (CDC) Methodology: API consumers define the contract they expect, and the provider must comply with it. This allows replacing slow and unstable E2E tests with fast checks using verified stubs, excluding network delays from the equation.
Tools: Pact remains the leader, but AI-based solutions are emerging that can automatically create contracts by analyzing traffic in staging environments, lowering the barrier to entry.
From Static Contracts to Behavior Validation
The next evolutionary step is the transition from static, manually maintained contracts (as in Pact) to dynamic behavior-based validation.
Problem: With AI increasing code churn, keeping static contract files up to date becomes increasingly unsustainable.
New Approaches and Solutions for Behavioral Validation:
- Abandoning mocks and statics (solving the "Mocking Hell" problem): Instead of writing and maintaining contract files, the system learns the "baseline behavior" of services by observing real interactions. This creates an "implicit contract."
- AI Semantic Diff: To compare responses, AI is used to perform semantic diffs. It distinguishes real breaking changes from minor changes (noise), assigning them a "Relevance Score."
- Ephemeral Environments: Tests run not on mock servers, but in isolated environments with real dependencies that are automatically spun up for each Pull Request.
Modern integration testing (Broad Integration Testing) increasingly uses containerization. Libraries like Testcontainers allow spinning up disposable instances of databases (PostgreSQL, Redis, Kafka) for each test run. This enables deep integration testing with real dependencies, achieving E2E-level reliability but with the speed and isolation of Unit tests. Container startup optimization has made this approach the de facto standard for backend verification.
Test execution speed is a critical factor. If a local run takes more than 5-10 minutes, developers stop running tests.
Self-Healing Tests and E2E
A key trend in E2E is using AI to combat locator fragility. If a developer changes a button ID, a traditional test fails. Tools with "self-healing" (e.g., integrated into Testim or plugins for Playwright) analyze the DOM tree and find the element by other features (text, position, neighbors), automatically updating the test.
However, adoption lags behind potential. The World Quality Report 2025-26 reports self-healing tests at 49% adoption among AI-enabled opportunities (base: 2,000) and explicitly warns that self-healing scripts remain underused, leaving teams with fragile pipelines and rising maintenance costs.
"Self-healing" will create a debate about what constitutes a defect. If an agent replaced a locator or click route and the test passes again, is this "test repair" or "regression masking"? The answer depends on the domain. Therefore, without rules and logging of edits, this approach is dangerous, even if the system is deterministic.
Safe AI-Native Workflows: Deterministic Test Execution
This is an approach that combines the flexibility of "Probabilistic AI" and the reliability of "Deterministic Execution." In this scenario, the Agent does not try to "guess" the test result. Instead, it acts as an orchestrator:
- The Agent makes a decision on which scenario to verify (understanding intentions).
- The Agent launches a deterministic tool (e.g., a Replay engine) that guarantees precise action reproduction.
- The Agent analyzes facts - precise execution data obtained from the tool.
This allows using AI as a "smart operator" that controls rigid automation infrastructure, eliminating hallucinations but maintaining adaptability.
Manual Review Requirements in Critical Systems
Despite automation, in critical areas (finance, medicine), having a human in the loop (HITL) remains a mandatory requirement. AI does not bear legal responsibility. A human signs off on the release. This creates a new bottleneck: AI creates tests faster than people can physically check and authorize them qualitatively.
Practical Recommendations for QA Teams
The industry is in an active transformation phase. To avoid drowning in technical debt generated by AI, companies should reconsider their QA approaches.
Reconsider Metrics: Code Coverage No Longer Works
Achieving high test coverage with AI has become too easy, but it doesn't guarantee quality.
What to Do: Shift focus from coverage percentage to Mutation Testing and Requirements Coverage. What matters is not how many lines are touched by a test, but whether the test fails if you break the logic.
Invest in Verification Infrastructure
AI creates tests instantly, but their execution can become a bottleneck.
What to Do: Implement Ephemeral Environments. For each Pull Request, an isolated environment with real databases (via Testcontainers) should be automatically spun up. This allows moving integration testing to the development stage.
Give AI Access to Context (Closing the Loop)
AI in IDE sees only static code. It "hallucinates" because it's disconnected from reality: it doesn't know what data is in the database or why a query failed.
Why: Context turns AI from a "text generator" into a "debugging engineer" capable of independently finding the cause of a failure in logs and fixing the test.
What to Do: Integrate agents with runtime. AI should get access to container logs, traces, and test execution results (e.g., via MCP servers) to analyze failure causes.
Closing the Loop: The Autonomous Quality Loop
In 2026, we don't just ask AI to "write code." we ask it to "solve the regression." This requires a new workflow, known as the Autonomous Quality Loop:
- Context Injection (MCP): The AI reads the failed production trace from BitDive. It sees the exact N+1 query or state corruption that caused the incident.
- Implementation: Informed by the real runtime data, the AI proposes a fix. It's not guessing; it's reacting to established facts.
- Behavior Verification: The agent compares the "before" trace with the "after" trace to verify the fix mathematically.
This turns the AI from a source of "technical slop" into a self-correcting engineering agent.
Next Steps for AI-Native Teams
- Bridge the Verification Gap: Learn how to connect Cursor to your JVM runtime.
- Eliminate Mocking Hell: Transition from manual mocks to Trace-Based Testing.
- Explore Terms: Visit our Engineering Glossary for more on Unexpected Behavior Changes and Real Runtime Data.
Checklist: Setting Up the AI Verification Loop
For teams using Cursor, Claude, or Windsurf, follow this pattern to close the loop:
- Expose Context: Connect BitDive to your IDE via the MCP Server.
- Analyze Failures: Instead of reading raw logs, ask the AI: "Analyze the failing trace from BitDive and show me the method parameters."
- Create & Validate: Have the AI propose a fix and then immediately run the Replay Scenario to verify the fix locally.
Validate AI-Generated Code Instantly
Ensure your AI-written code does exactly what it should. Capture real behavior and create regression tests without writing a single line of code.
Try BitDive TodayConclusion
The main challenge of 2026 is learning to validate code faster than AI can create it.
We are moving away from a model where a human writes both code and tests, to a model where a human defines intentions, and AI implements them under the supervision.